해당 자료는 "모두를 위한 머신러닝/딥러닝 강의"를 보고 개인적으로 정리한 내용입니다.
hunkim.github.io
본 실습의 tensorflow는 1.x 버전입니다.
이론
가설
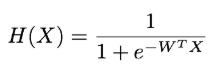
Cost함수
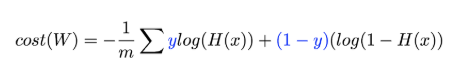
최적화를 위한 경사하강법
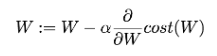
Logistic Classification을 Tensorflow로 구현
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#tensorflow v1호환
x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3], [6, 2]]
y_data = [[0], [0], [0], [1], [1], [1]]
X = tf.placeholder(tf.float32, shape=[None, 2])
Y = tf.placeholder(tf.float32, shape=[None, 1])
#W의 경우 X변수 2개, 나가는 Y변수 1개 이므로, [2,1]로 정의(매트릭스 곱)
W = tf.Variable(tf.random_normal([2, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# 가설을 코드로 구현
# X변수가 2개이므로, MATRIX 곱셈으로 간단하게 표현 가능
# Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W) + b))
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
#Cost 함수를 코드로 구현
# cost/loss function
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) *
tf.log(1 - hypothesis))
#미분을 통해 경사하강법으로 W,b를 구하는 로직을 코드로 구현
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
# hypothesis는 0~1사의의 소수점이 나올 수 있기 때문에, 0.5 기준으로 True, False로 predicted
# cast 하므로 True = 1, False=0으로 변환되어 predicted에 저장
# True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
# 아래부터는 모델을 위한 학습
with tf.Session() as sess:
# Initialize TensorFlow variables
sess.run(tf.global_variables_initializer())
for step in range(10001):
cost_val, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, cost_val)
# Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy],
feed_dict={X: x_data, Y: y_data})
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a)
 ML_lab_05_1.ipynb
0.01MB
ML_lab_05_1.ipynb
0.01MB
당뇨병 샘플을 파일로 입력받아 예측
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
#tensorflow v1호환
import numpy as np
xy = np.loadtxt('data-03-diabetes.csv', delimiter=',', dtype=np.float32)
x_data = xy[:, 0:-1]
y_data = xy[:, [-1]]
# 파일로 주어진 data-03-diabetes.csv 에 8개의 X변수가 있으므로 shape는 [None, 8]로 선언
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 8])
Y = tf.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random_normal([8, 1]), name='weight')
b = tf.Variable(tf.random_normal([1]), name='bias')
# Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W)))
hypothesis = tf.sigmoid(tf.matmul(X, W) + b)
# cost/loss function
cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * tf.log(1 - hypothesis))
train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)
# Accuracy computation
# True if hypothesis>0.5 else False
predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32)
accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32))
# Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
feed = {X: x_data, Y: y_data}
for step in range(10001):
sess.run(train, feed_dict=feed)
if step % 200 == 0:
print(step, sess.run(cost, feed_dict=feed))
# Accuracy report
h, c, a = sess.run([hypothesis, predicted, accuracy], feed_dict=feed)
print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a)

'도서,강의 요약 > 모두를 위한 머신러닝' 카테고리의 다른 글
| ML lec 6-2: Softmax classifier 의 cost함수 (0) | 2020.05.30 |
|---|---|
| ML lec 6-1 - Softmax Regression: 기본 개념 소개 (0) | 2020.05.28 |
| ML lec 5-2 Logistic Regression의 cost 함수 설명 (0) | 2020.05.24 |
| ML lec 5-1: Logistic Classification의 가설 함수 정의 (0) | 2020.05.19 |
| ML lab 04: multi-variable linear regression을 TensorFlow에서 구현하기 (0) | 2020.05.12 |



